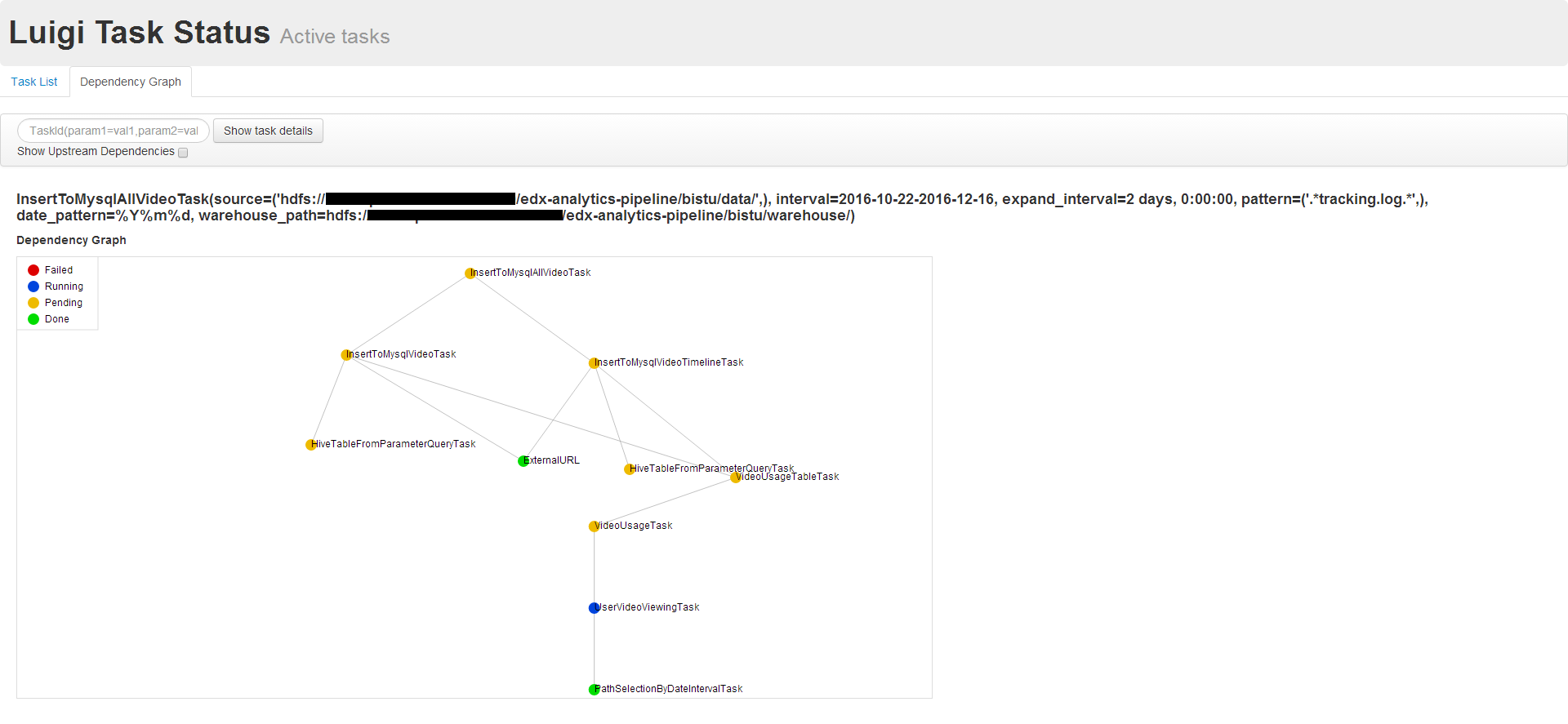
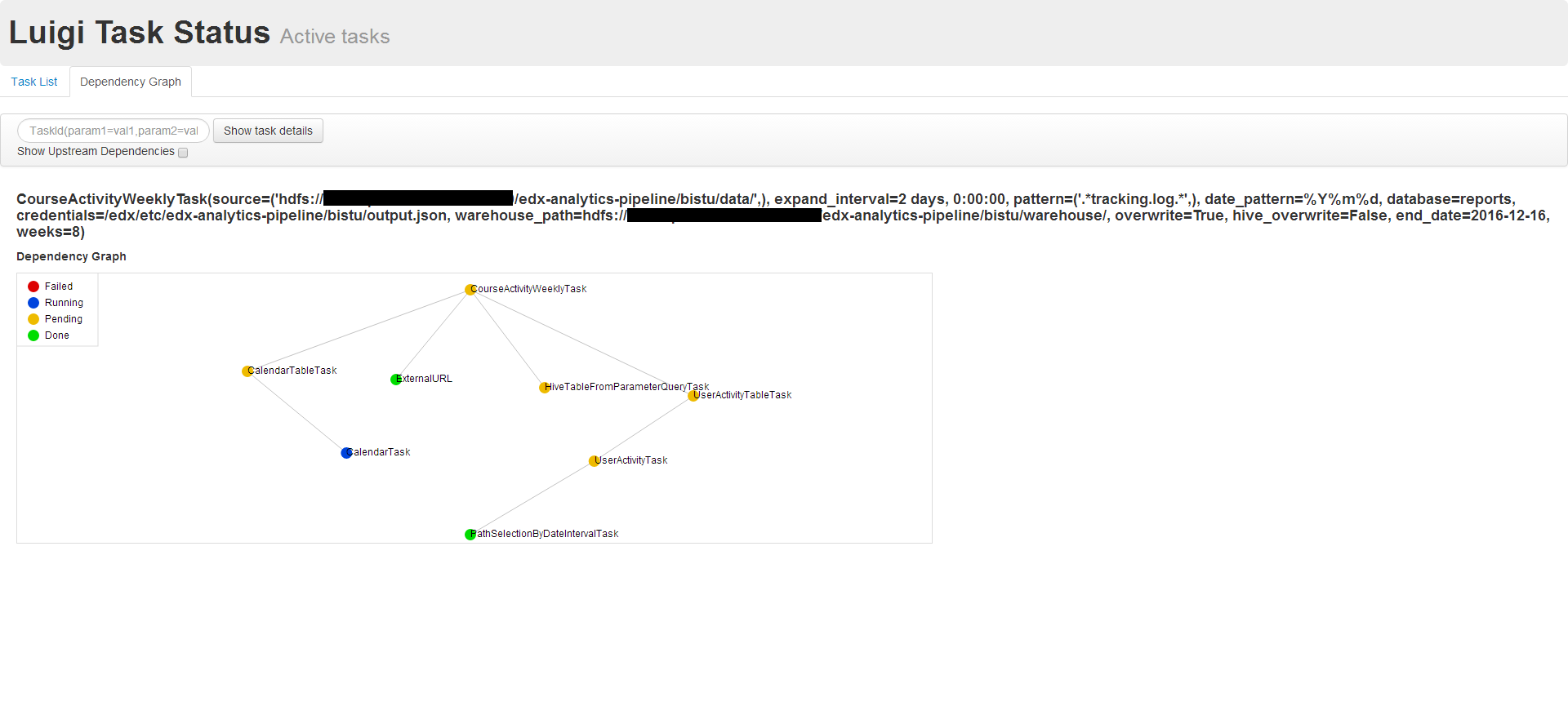
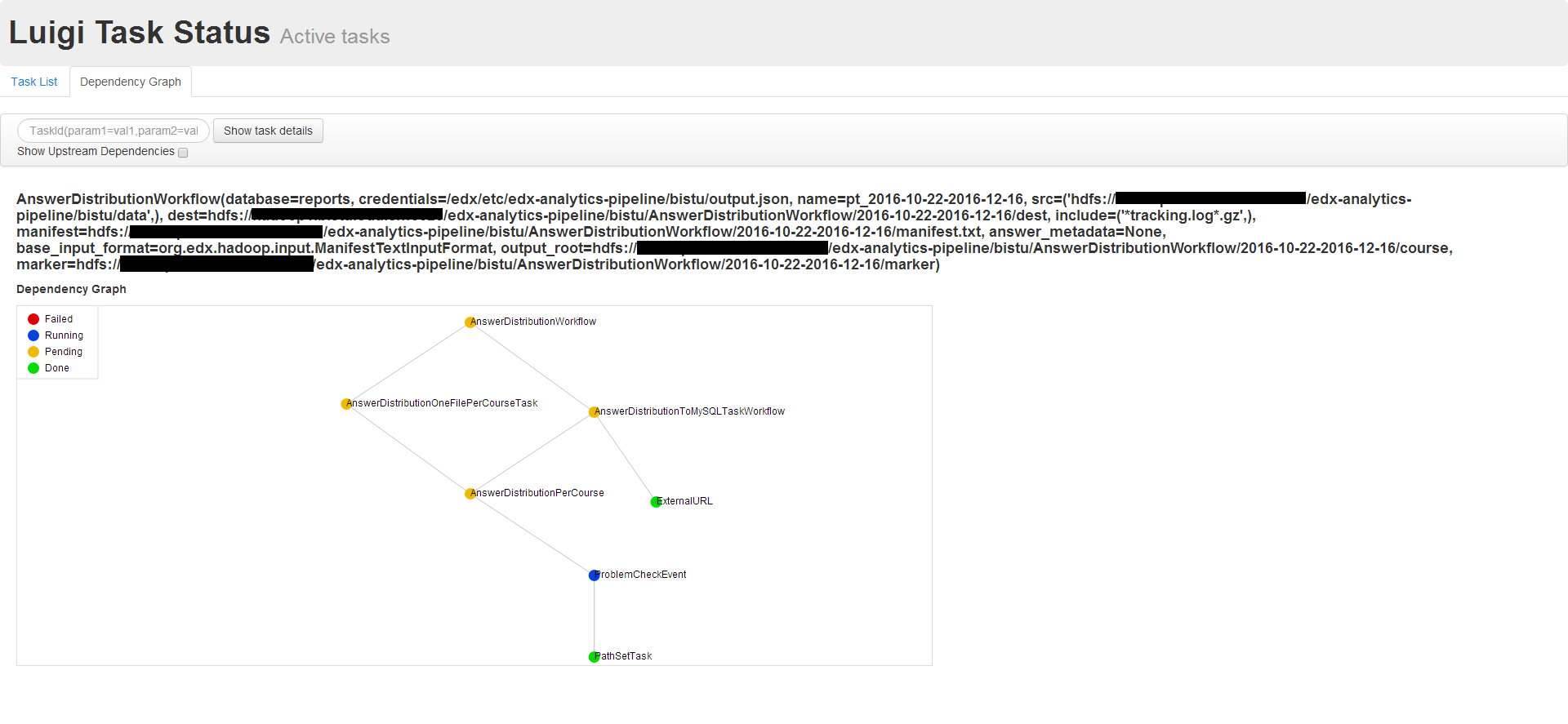
hadoop任务出错
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Diagnostics: Exception from container-launch. Container id: container_1528273359898_0016_02_000001 Exit code: 255 Stack trace: ExitCodeException exitCode=255: at org.apache.hadoop.util.Shell.runCommand(Shell.java:545) at org.apache.hadoop.util.Shell.run(Shell.java:456) at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:722) at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:212) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302) at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:748) |
但是看userlog下无日志
追查好久后发现任务结束居然会自动删container的日志,MDZZ
然后使用watch -n 'cp -r ./* ..'把日志考出去
发现错误日志如下
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 |
2018-06-06 22:33:55,095 ERROR [ContainerLauncher #0] org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl: Container launch failed for container_1528273359898_0015_01_000002 : java.lang.IllegalArgumentException: Does not contain a valid host:port authority: Insights.Ginkgo.2:35639 at org.apache.hadoop.net.NetUtils.createSocketAddr(NetUtils.java:213) at org.apache.hadoop.net.NetUtils.createSocketAddr(NetUtils.java:164) at org.apache.hadoop.net.NetUtils.createSocketAddr(NetUtils.java:153) at org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy$ContainerManagementProtocolProxyData.newProxy(ContainerManagementProtocolProxy.java:258) at org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy$ContainerManagementProtocolProxyData.<init>(ContainerManagementProtocolProxy.java:244) at org.apache.hadoop.yarn.client.api.impl.ContainerManagementProtocolProxy.getProxy(ContainerManagementProtocolProxy.java:129) at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl.getCMProxy(ContainerLauncherImpl.java:409) at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$Container.launch(ContainerLauncherImpl.java:138) at org.apache.hadoop.mapreduce.v2.app.launcher.ContainerLauncherImpl$EventProcessor.run(ContainerLauncherImpl.java:375) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:748) |
????黑人问号,不过总算找到问题根源了
但是Insights.Ginkgo.2:35639这个地址咋了??
网上说是没配置jobhistory的地址,但是这个服务器是克隆的镜像啊,之前也没配置过啊
在mapred-site.xml加上下面的配置
|
0 1 2 3 4 5 |
<property> <name>mapreduce.jobhistory.address</name> <value>localhost:7001</value> <description>job history server</description> </property> |
搜了下这个名字在hadoop配置文件没找到
查了下当前主机hostname是Insights
而/etc/hosts写的是
127.0.0.1 localhost
127.0.1.1 Insights.Ginkgo.2 Insights
尝试改成这样重启hadoop再试
127.0.0.1 localhost
127.0.1.1 Insights Insights.Ginkgo.2
成功了!!!不过不知道是哪个影响的,需要后续再确认下
另外Insights数据分析配置中override.cfg,新的配置格式有点变化
|
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[database-export] database = reports credentials = /edx/etc/edx-analytics-pipeline/output.json [database-import] database = edxapp credentials = /edx/etc/edx-analytics-pipeline/input.json destination = hdfs://localhost:9000/edx-analytics-pipeline/ [map-reduce] engine = hadoop marker = hdfs://localhost:9000/marker/ remote_log_level = DEBUG [event-logs] pattern = [".*tracking.log-(?P<date>\\d{8}).*\\.gz"] expand_interval = 2 days source = ["hdfs://localhost:9000/data"] |
注意pattern和source变成了json,反斜杠要转义一次的,但是也不能写\\\\否则读到pathutil.py中的正则会多一层转义,要写成图中的样子,这格式是re包的正则,不是shell中的正则,所以开头是.*不是*