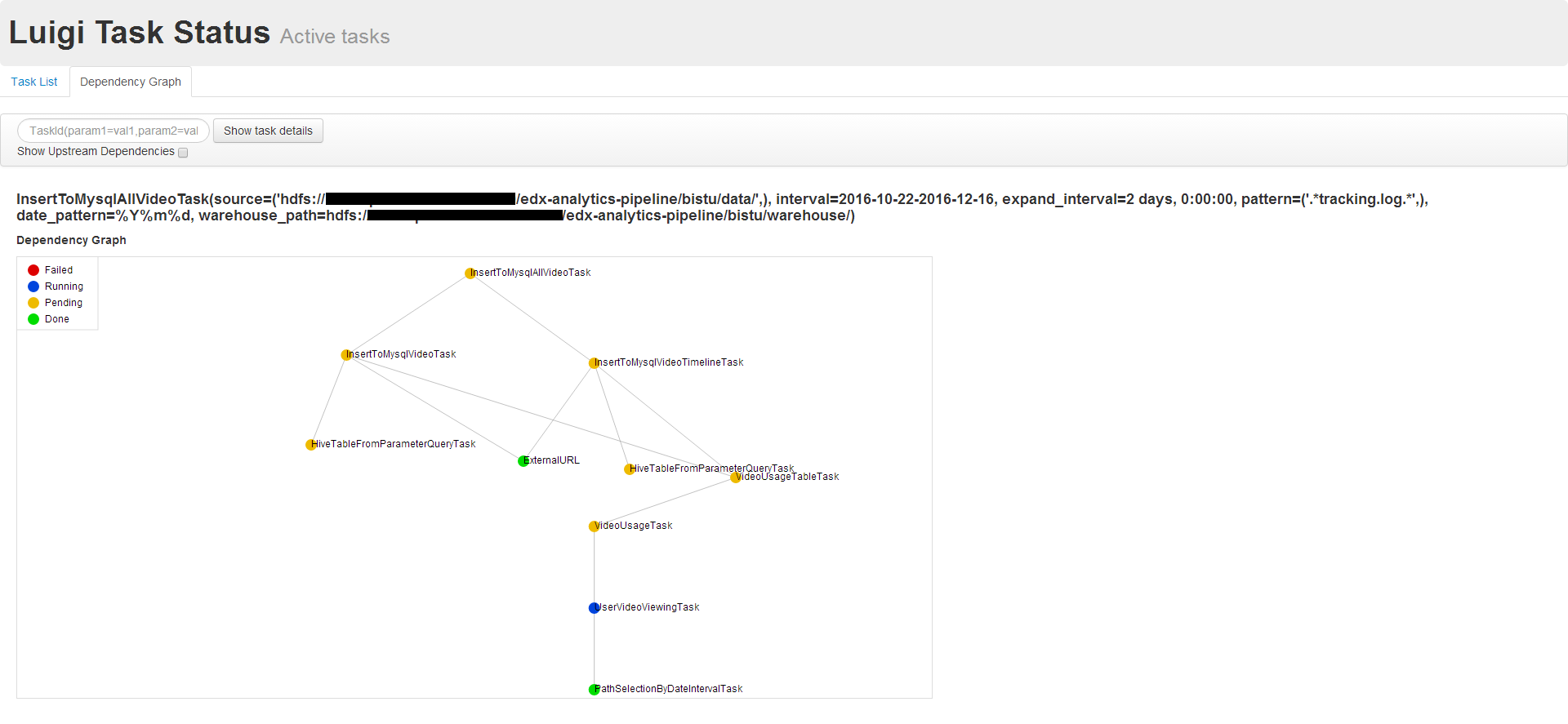
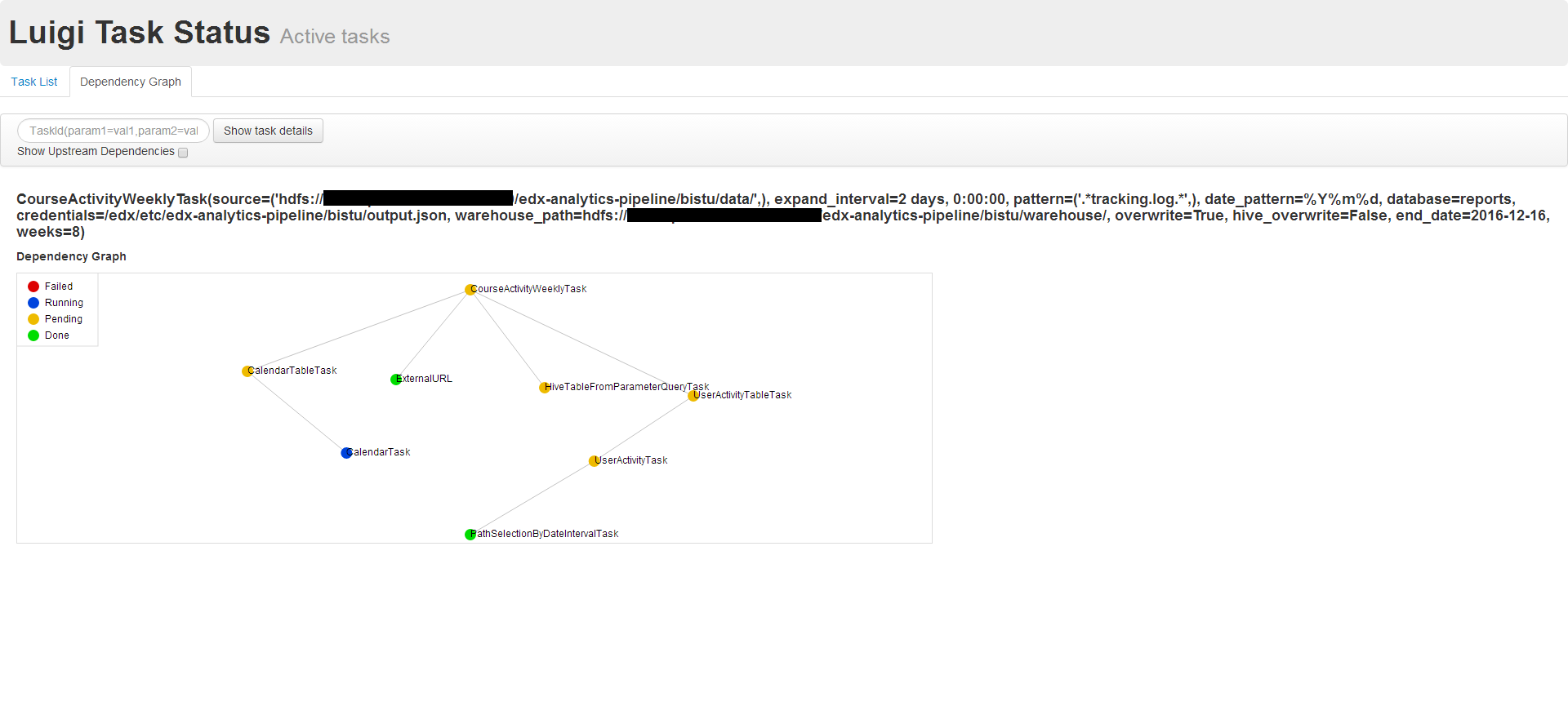
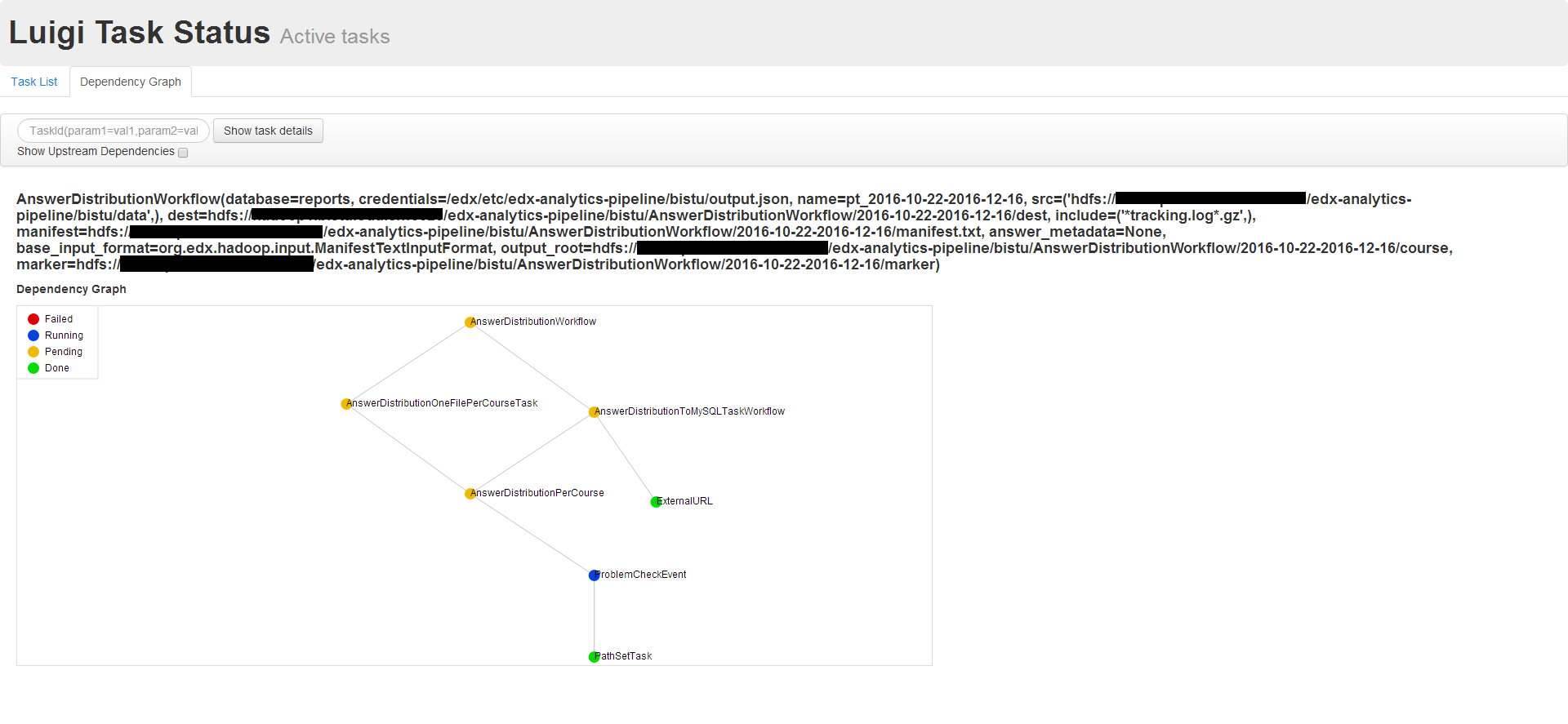
为了增加pipeline的运算速度,所以利用集群来进行日志的分析统计。测试数据规模:某机构edX的D版在真实场景下一年多使用记录。
开始日期 2016/11/27
开始时间 2:26:00
结束日期 2016/11/28
结束时间 3:34:00
总时间 23:10:54
日志开始日期 2015/6/7
日志结束日期 2016/11/24
在没有任何设置的情况下,运行完所有任务的时间如上表。。。。将近一天的时间=-=太慢了。
经过不断的尝试、分析如下:
慢的原因是每个任务都会有很多的map和reduce任务生成、而每个mapreduce任务都会占用一个worker节点的容器、每个服务器能申请到的容器数量和每个mapreduce占用的内存CPU资源,决定了同时运行的容器数量。
所以,想提高速度,就要尽可能多的让每个mapreduce节省内存、让容器的大小和mapreduce任务所需内存大小尽可能相等。
以我实验的集群规模为例进行参数设置方法。
1.资源计算
3台worker服务器,每个服务器CPU有8个core,16GB内存。
所以一共有24个CPU核心、48GB内存
虚拟cpu系数定为2,每个服务器预留两个核心给操作系统
所以每个服务器CPU vcore数量为8 * 2 – 2 = 14
内存留8G给操作系统,剩下12GB给Container
所以总memory为12 * 3 = 36GB
2.参数配置
需要配置YARN的参数如下(均为CDH5中YARN2的配置)
yarn.app.mapreduce.am.resource.mb 1024//这是Resource Manager需要的内存、我给了1G
yarn.app.mapreduce.am.resource.cpu-vcores 2//这是Resource Manager需要的CPU、我给了2
ApplicationMaster Java 最大堆栈 819.2 //这个数字是yarn.app.mapreduce.am.resource.mb * 0.8得到的
mapreduce.map.memory.mb 640 //这个是每个map任务需要的内存,实测在512时候会有个reduce任务失败,所以给了600多
mapreduce.map.cpu.vcores 2 //这个是每个map任务需要的CPU
mapreduce.reduce.memory.mb 640 //这个是每个reduce任务需要的内
mapreduce.reduce.cpu.vcores 2 //这个是每个reduce任务需要的CPU
mapreduce.map.java.opts.max.heap 512 //这是mapreduce.map.memory.mb * 0.8得到的
mapreduce.reduce.java.opts.max.heap 512 //这是mapreduce.reduce.memory.mb * 0.8得到的
客户端 Java 堆大小(字节) 512 //这里的客户端指的是yarn客户端的大小
JobHistory Server 的 Java 堆栈大小(字节) 1024
NodeManager 的 Java 堆栈大小(字节) 512
yarn.nodemanager.resource.memory-mb 12288 //这个是刚刚说的12G
yarn.nodemanager.resource.cpu-vcores 14 //这是刚刚说的14个vcore
ResourceManager 的 Java 堆栈大小(字节) 1024
yarn.scheduler.minimum-allocation-mb 1024 //一个容器最小内存占用
yarn.scheduler.increment-allocation-mb 128 //一个容器每次多申请多少内存
yarn.scheduler.maximum-allocation-mb 2048 //一个容器最大内存占用
yarn.scheduler.minimum-allocation-vcores 1 //一个容器最小CPU占用
yarn.scheduler.increment-allocation-vcores 1 //一个容器每次多申请多少CPU
yarn.scheduler.maximum-allocation-vcores 4 //一个容器最大内存占用
这样配置的实验结果时间为
开始日期 2016/12/2
开始时间 12:02:00
结束日期 2016/12/2
结束时间 15:34:00
总时间 3:06:50
日志开始日期 2015/6/7
日志结束日期 2016/11/24
比最开始节省了很多时间。。。因为同时在运行的container增加了,所以速度也变快了。
问题:发现map任务的数量每次处理的数据并不多,能不能合并一些数据,而不是每个map只处理一个文件?并且内存占用我觉得还可以在省一些,因为每个map的数据量不是很大。。。待解决=-=