计组期末总结系列1——数的表示
————————下面是一些开头的废话,可以不看————————
由于电脑坏了,又不能整天玩手机,舍友说计组不会,为了方便同学复习,同时总结一下整个学期学习的内容,所以决定写写一些重点的内容(虽然导论、C语言、电路都讲过三遍了,然而还是可以有人不会啊╮(╯▽╰)╭)。另,本人水平有限,如果文中有错误还请批评指正。
——————我是分割线,上面的废话可以不看,下面才是重点————————
在计算机中,所有的数字都是用二进制来表示的,为了理解记忆而不去记忆大量的公式,不得不从头好好思考二进制。
我们都知道在十进制中,以一个数字为例:1234.4321,想想这个数字的含义,如果什么都不说,我们都会默认这是一个十进制的数字。1234.4321 = 1234 +0.4321,可以分成两个部分来表示,也就是整数部分和小数部分。我们分别来看这两个部分。
1234 = 1 * 1000 + 2 * 100 + 3 * 10 + 4 * 1
= 1 * 10^3 + 2 * 10^2 + 3 * 10^1 + 4 * 10^0
每一位代表着不同的意义,从右往左看
第0位的数字代表了有多少个1,也就是10^0
第1位的数字代表了有多少个10,也就是10^1
第2位的数字代表了有多少个100,也就是10^2
第3位的数字代表了有多少个1000,也就是10^3
以此类推
0.4321 = 4 * 0.1 + 3 * 0.01 + 2 * 0.001 + 1 * 0.0001
= 4 * 10^-1 + 3 * 10^-2 + 2 * 10^-3 + 1 * 10^-4
小数点后的部分,从左往右看
第0位的数字代表了有多少个0.1,也就是10^-1
第1位的数字代表了有多少个0.01,也就是10^-2
第2位的数字代表了有多少个0.001,也就是10^-3
第3位的数字代表了有多少个0.0001,也就是10^-4
上面所说的十进制代表了每位数字的权值都是10的幂次。
同理类推到二进制。
以1010.1001为例
1010.1001 = 1010 + 0.1001
整数部分,从右往左看
1010 = 1 * 8 + 0 * 4 + 1 * 2 + 0 * 1
= 1 * 2^3 + 0 * 2^2 + 1 * 2^1 + 0 * 2^0
第0位的数字代表了有多少个1,也就是2^0
第1位的数字代表了有多少个2,也就是2^1
第2位的数字代表了有多少个4,也就是2^2
第3位的数字代表了有多少个8,也就是2^3
小数点后的部分,从左往右看
0.1001 = 0.1 + 0.00 + 0.000 + 0.0001
=1 * 2^-1 + 0 * 2^-2 + 0 * 2^-3 + 1 * 2^-4
第0位的数字代表了有多少个0.5,也就是2^-1
第1位的数字代表了有多少个0.25,也就是2^-2
第2位的数字代表了有多少个0.125,也就是2^-3
第3位的数字代表了有多少个0.0625,也就是2^-4
八进制和十六进制同理。
进制之间的转换:
十进制 二进制 八进制 十六进制
如果你理解了上面所述的含义,那么转换也会非常容易理解。不同进制数字的含义最终都是为了表示数字,换句话说也就是一个数字可以以不同的方式表示出来。
十进制转二进制方法
以1234.4321为例进行说明。
整数部分的转换:
由于二进制每位的权值都是2的幂次,所以为了方便转化可以先写出几个算好的2幂次结果
| 2^10 |
2^9 |
2^8 |
2^7 |
2^6 |
2^5 |
2^4 |
2^3 |
2^2 |
2^1 |
2^0 |
| 1024 |
512 |
256 |
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
寻找小于1234且尽可能大的数或者等于1234的位写1,如下表
| 2^10 |
2^9 |
2^8 |
2^7 |
2^6 |
2^5 |
2^4 |
2^3 |
2^2 |
2^1 |
2^0 |
| 1024 |
512 |
256 |
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
| 1 |
|
|
|
|
|
|
|
|
|
|
用1234 – 1024 = 210
寻找小于210且尽可能大的数或者等于210的位继续写1,如下表
| 2^10 |
2^9 |
2^8 |
2^7 |
2^6 |
2^5 |
2^4 |
2^3 |
2^2 |
2^1 |
2^0 |
| 1024 |
512 |
256 |
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
| 1 |
|
|
1 |
|
|
|
|
|
|
|
用210 – 128 = 82
寻找小于82且尽可能大的数或者等于82的位继续写1,如下表
| 2^10 |
2^9 |
2^8 |
2^7 |
2^6 |
2^5 |
2^4 |
2^3 |
2^2 |
2^1 |
2^0 |
| 1024 |
512 |
256 |
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
| 1 |
|
|
1 |
1 |
|
|
|
|
|
|
用82 – 64 = 18
寻找小于18且尽可能大的数或者等于18的位继续写1,如下表
| 2^10 |
2^9 |
2^8 |
2^7 |
2^6 |
2^5 |
2^4 |
2^3 |
2^2 |
2^1 |
2^0 |
| 1024 |
512 |
256 |
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
| 1 |
|
|
1 |
1 |
|
1 |
|
|
|
|
用18 – 16 = 2
寻找小于2且尽可能大的数或者等于2的位继续写1,如下表
| 2^10 |
2^9 |
2^8 |
2^7 |
2^6 |
2^5 |
2^4 |
2^3 |
2^2 |
2^1 |
2^0 |
| 1024 |
512 |
256 |
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
| 1 |
|
|
1 |
1 |
|
1 |
|
|
1 |
|
最后,剩余位写0,结果就是转换成二进制的整数部分。
| 2^10 |
2^9 |
2^8 |
2^7 |
2^6 |
2^5 |
2^4 |
2^3 |
2^2 |
2^1 |
2^0 |
| 1024 |
512 |
256 |
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
| 1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
结果为 10011010010
小数部分0.4321,进行乘二取整。
0.4321 * 2 = 0.8642 整数部分为0
0.8642 * 2 = 1.7284 整数部分为1
0.7284 * 2 = 1.4568 整数部分为1
0.4568 * 2 = 0.9136 整数部分为0
0.9136 * 2 = 1.8272 整数部分为1
以此类推直到小数部分为零,把上面取到的整数部分从左到右排列即是二进制小数0.01101,注意,需要几位就算几次。
其他的转换:
二进制,八进制,十六进制之间都可以方便的进行转换,因为每三位二进制数字相当于八进制的一位数字,每四位相当于十六进制的一位数字。
定点整数的表示
首先,在计算机中所有的数字都是二进制储存的,但是,为了方便书写和节省位数一般用十六进制来表示,两位就能表示八位的二进制数字。
编码有三种,原码,反码,补码。接下来详细说明。为了方便观察,我们在能观察规律的情况下尽可能缩短长度来说明。
由于有正数和负数,所以需要一位标识位来区分是正数还是负数。先说原码,取字长位三位,其中第一位是符号位,0代表正1代表负,那么它可以表示的数字是这样的、
|
原码 |
真值 |
| 0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
0 |
1 |
1 |
| 2 |
0 |
1 |
0 |
2 |
| 3 |
0 |
1 |
1 |
3 |
|
|
|
|
|
| 4 |
1 |
0 |
0 |
-0 |
| 5 |
1 |
0 |
1 |
-1 |
| 6 |
1 |
1 |
0 |
-2 |
| 7 |
1 |
1 |
1 |
-3 |
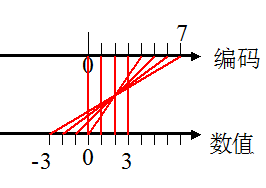
表中第一列是单纯作为二进制来看这三位数的十进制数字。原码的特点非常容易看出来,有两个0,一个是100一个是000,都是代表了0,表达的范围是对称的。计算方法也很好理解,由于只有2位可以用来表示数本身,所以可以表示的数范围就是0 ~(2^2)-1也就是0~3,算上负数的那部分也就是-3~+3,推广一下很容易得到范围的公式,-((2^n)-1)~+(2^n)-1,也就是1-2^n~2^n-1,其中的n是不算符号位在内的位数。
最大的正数是011,也就是3,
最小的正数是001,也就是1
最大的负数(绝对值最小的负数)是101,也就是-1
最小的负数(绝对值最大的负数)是111,也就是-3
接下来是反码,需要注意的是,正数的反码和原码一样,正数的反码和原码一样,正数的反码和原码一样,负数的反码就是把原码按位取反得到的,符号位不变。符号位不变。符号位不变。(重要的事情说三遍)效果如下表
|
反码 |
真值 |
| 0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
0 |
1 |
1 |
| 2 |
0 |
1 |
0 |
2 |
| 3 |
0 |
1 |
1 |
3 |
|
|
|
|
|
| 7 |
1 |
1 |
1 |
-0 |
| 6 |
1 |
1 |
0 |
-1 |
| 5 |
1 |
0 |
1 |
-2 |
| 4 |
1 |
0 |
0 |
-3 |
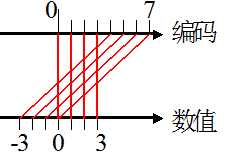
显然,范围没变,但是对应关系有了一些变化,和原码表示相同的是,0依然有可以有2个编码来表示。
最后是补码,正数的补码和原码一样。正数的补码和原码一样。正数的补码和原码一样。负数的补码是在它的反码基础上再加1,这个加1的运算符号位要参与运算。这个加1的运算符号位要参与运算。这个加1的运算符号位要参与运算。效果如下。
|
补码 |
真值 |
| 0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
0 |
1 |
1 |
| 2 |
0 |
1 |
0 |
2 |
| 3 |
0 |
1 |
1 |
3 |
|
|
|
|
|
| 0 |
0 |
0 |
0 |
0 |
| 7 |
1 |
1 |
1 |
-1 |
| 6 |
1 |
1 |
0 |
-2 |
| 5 |
1 |
0 |
1 |
-3 |
结果会发现还有一个编码空着,就是100,所以规定用100表示-4,如下表
|
补码 |
真值 |
| 0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
0 |
1 |
1 |
| 2 |
0 |
1 |
0 |
2 |
| 3 |
0 |
1 |
1 |
3 |
|
|
|
|
|
| 0 |
0 |
0 |
0 |
0 |
| 7 |
1 |
1 |
1 |
-1 |
| 6 |
1 |
1 |
0 |
-2 |
| 5 |
1 |
0 |
1 |
-3 |
| 4 |
1 |
0 |
0 |
-4 |
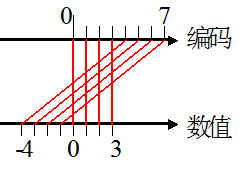
这样既可以多表示一个数字,扩大了表示范围,还统一了0的编码。并且用补码表示还有一个特点,仔细观察上面的表格,如果用111+001,结果将会是000,高位会直接溢出而消失。正好和-1+1 = 0吻合。所以计算机中都用二进制补码来表示数字。补码能表示的范围显然是-(2^2)~2^2-1,推广下就是-(2^n)~2^n-1,其中的n依然不包括符号位在内。
最大的正数是011,也就是3,
最小的正数是001,也就是1,
最大的负数(绝对值最小的负数)是111,也就是-1,到此为止和原码一样
最小的负数(绝对值最大的负数)是100,也就是-4,
注意:这个数字很特殊,真值不能直接求原码来算。可以由以下两种思路来理解。
第一种:按照原码中最小的负数再减1来计算。比如
三位的编码最小的负数用原码表示为111,是-3,那么这个数就代表的是-4
四位编码中最小的负数用原码表示为1111,是-7,那么1000就代表-8
第二种:按照一对儿相反数相加为0来考虑。
寻找一个和100相加为000的数,那么是一定是100,把这个100当成二进制编码来换成十进制,也就是4,那么补码100代表的就是-4
简化过程就可以直接把补码100当成二进制转换,结果再取反即可得到补码100的真值。
再比如补码1000,转成十进制就是8,那么它表示的真值就是8的相反数-8
注意总结上面的规律(前提条件是以补码表示)
最大的正数:
符号位一定是0,由于要求是最大,所以剩下的位数都是1即可,以8位编码为例,最大的正数就是0111 1111。可以按权值展开计算真值,但是这里有个小技巧,可以先把这个数加1,结果是1000 0000,然后转换,结果是2^7 = 128,之后再减1,也就是127。所以考试如果出现n位的话可以直接写出结果,也就是2^(n-1)-1。
最小的正数就不用说了,一定是1。
最大的负数(绝对值最小的负数):
有几位就写几位1,以8位编码举例,就写8个1,也就是 1111 1111,真值以上面第二种思路来理解非常方便,结果是-1.
最小的负数(绝对值最大的负数):
符号位一定是1,剩下几位写几个0。以8位编码为例,就写1000 0000,真值类比上面的思路来求,结果是-128。
这几个数在数轴上的位置如下图

接下来说说定点小数的表示。
在十进制中,表示的方法都很熟悉了,但是一定要仔细思考含义,才能理解二进制中定点小数的表示。
十进制中:把1个1分成10份,其中的一份就表示为0.1,如果分成100份,其中的一份就是0.01,如果分成1000份,其中的一份就是0.001
二进制中同理,把1个1分成2份,其中的一份就表示为0.1,如果分成4份,其中的一份就是0.01,如果分成8份,其中的一份就是0.001
注意虽然写出来一样,但是含义完全变了。
由于是小数,所以整数部分是0,延续定点整数的思路,把这位数当做符号标识,称为符号位。类比前面整数部分,依然可以有如下的三种表示方法,按顺序分别是原码,反码,补码。依然以3位编码为例。
|
原码 |
真值 |
|
| 0 |
0 |
0 |
0 |
0.00 |
0.00 |
| 1 |
0 |
0 |
1 |
0.25 |
2^-2 |
| 2 |
0 |
1 |
0 |
0.50 |
2^-1 |
| 3 |
0 |
1 |
1 |
0.75 |
(2^-1)+(2^-2) |
|
|
|
|
|
|
| 4 |
1 |
0 |
0 |
-0.00 |
-0.00 |
| 5 |
1 |
0 |
1 |
-0.25 |
-2^-2 |
| 6 |
1 |
1 |
0 |
-0.50 |
-2^-1 |
| 7 |
1 |
1 |
1 |
-0.75 |
-((2^-1)+(2^-2)) |
最大的正数是011,也就是0.75,
最小的正数是001,也就是0.25,
最大的负数(绝对值最小的负数)是101,也就是-0.25,
最小的负数(绝对值最大的负数)是111,也就是-0.75,
|
反码 |
真值 |
|
| 0 |
0 |
0 |
0 |
0.00 |
0.00 |
| 1 |
0 |
0 |
1 |
0.25 |
2^-2 |
| 2 |
0 |
1 |
0 |
0.50 |
2^-1 |
| 3 |
0 |
1 |
1 |
0.75 |
(2^-1)+(2^-2) |
|
|
|
|
|
|
| 7 |
1 |
1 |
1 |
-0.00 |
-0.00 |
| 6 |
1 |
1 |
0 |
-0.25 |
-2^-2 |
| 5 |
1 |
0 |
1 |
-0.50 |
-2^-1 |
| 4 |
1 |
0 |
0 |
-0.75 |
-((2^-1)+(2^-2)) |
|
补码 |
真值 |
|
| 0 |
0 |
0 |
0 |
0.00 |
0.00 |
| 1 |
0 |
0 |
1 |
0.25 |
2^-2 |
| 2 |
0 |
1 |
0 |
0.50 |
2^-1 |
| 3 |
0 |
1 |
1 |
0.75 |
(2^-1)+(2^-2) |
|
|
|
|
|
|
| 0 |
0 |
0 |
0 |
-0.00 |
-0.00 |
| 7 |
1 |
1 |
1 |
-0.25 |
-2^-2 |
| 6 |
1 |
1 |
0 |
-0.50 |
-2^-1 |
| 5 |
1 |
0 |
1 |
-0.75 |
-((2^-1)+(2^-2)) |
同理,补码空余出了一个编码就是100,所以规定用100来表示-1、用100来表示-1、用100来表示-1
|
补码 |
真值 |
|
| 0 |
0 |
0 |
0 |
0.00 |
0.00 |
| 1 |
0 |
0 |
1 |
0.25 |
2^-2 |
| 2 |
0 |
1 |
0 |
0.50 |
2^-1 |
| 3 |
0 |
1 |
1 |
0.75 |
(2^-1)+(2^-2) |
|
|
|
|
|
|
| 0 |
0 |
0 |
0 |
-0.00 |
-0.00 |
| 7 |
1 |
1 |
1 |
-0.25 |
-2^-2 |
| 6 |
1 |
1 |
0 |
-0.50 |
-2^-1 |
| 5 |
1 |
0 |
1 |
-0.75 |
-((2^-1)+(2^-2)) |
| 4 |
1 |
0 |
0 |
-1 |
|
最大的正数是011,也就是0.75,
最小的正数是001,也就是0.25,
最大的负数(绝对值最小的负数)是111,也就是-0.25,到此为止和原码一样
最小的负数(绝对值最大的负数)是100,也就是-1,
注意:这个数字很特殊,真值不能直接求原码来算。
注意总结上面的规律(前提条件是以补码表示)
最大的正数:
符号位一定是0,由于要求是最大,所以剩下的位数都是1即可,以8位编码为例,最大的正数就是0111 1111。可以按权值展开计算真值,但是这里有个小技巧,可以先把这个数加0000 0001,结果是1000 0000,然后转换,结果是1,之后再减0000 0001,也就是1-2^-7。所以考试如果出现n位的话可以直接写出结果,也就是1-2^-n。其中的n不算符号位
最小的正数:
符号位一定是0,由于要求最小,所以把权值最小的最低位直接写1,以8位编码为例,结果是0000 0001,表示2^-7
最大的负数(绝对值最小的负数):
符号位一定是1,剩下几位写几个1。以8位编码为例,就写1111 1111,真值类比上面的思路来求,结果是-(1-2^-7)。
最小的负数(绝对值最大的负数):
符号位一定是1,剩下几位就写几个0,以8位编码为例,就是1000 0000,那么它一定是-1。
画张图更好理解这四个数字的位置。

最后是浮点数。
把定点整数和定点小数结合起来表示,就是浮点数。它的原理类似于科学计数法,比如1.5*10^50,那么只需要把1.5和50记下来,就能描述一个非常大的数字,同理也可以描述非常小的数字,指数部分就相当于记录了小数点的位置。所以仿照这个方法,也可以把一个数表示成0.8*2^30的形式,再记录下0.8和30两个部分来表示这个很大的数字,这就是浮点数的表示法。前面的部分称之为尾码,指数部分称之为阶码。尾码部分用上面的定点小数来表示,指数部分用定点整数来表示。阶码在前尾码在后,组合后的编码就是浮点数的编码。
浮点数的表示范围由于受尾码影响,所以和定点小数范围类似,但是又因为阶码的存在扩大了范围,所以在非常接近0的部分是无法表示的。可以看出,尾码的正负决定了整个浮点数的正负,阶码的大小决定了与0的距离。仔细思考这句话,你就能准确的找到浮点数的表示范围。要时刻记得阶码当成定点整数尾码当成定点小数。

下面以8位浮点数编码为例,规定前4位为阶码,1位符号位,后4位为尾码,1位符号位。均以补码表示
最大的正数:
要求阶码是最大的正数,
同时尾码也是最大的正数。
结果是0111 0111,
前4位当成定点整数求真值,为2^3-1 = 7
后4位当成定点小数求真值,为1-2^-3 = 0.875(注:如果幂次太高可以不算结果),
所以最终表示的真值是0.875*2^7
最小的正数:
要求阶码为最小的负数(绝对值最大负数),
同时尾码为最小的正数。
结果是1000 0001,
前4位当成定点整数求真值,为-2^3 = -8
后4位当成定点小数求真值,为2^-3 = 0.125,
所以最终表示的真值是0.125*2^-8
最大的负数(绝对值最小的负数):
要求阶码为最小的负数(绝对值最大负数),
同时尾码为最大的负数(绝对值最小负数)。
结果是1000 1111,
前4位当成定点整数求真值,为-2^3 = -8
后4位当成定点小数求真值,为-2^-3 =-0.125,
所以最终表示的真值是-0.125*2^-8
最小的负数(绝对值最大的负数):
要求阶码为最大的正数,
同时尾码为最小的负数(绝对值最大负数)。
结果是0111 1000,
前4位当成定点整数求真值,为2^3-1 = 7
后4位当成定点小数求真值,为-1,所以最终表示的真值是-1*2^7
综上所述,浮点数的范围为-1*2^7~-0.125*2^-8 0.125*2^-8~0.875*2^7
但是为了提高运算精度,所以做了规格化(证明略),受影响的就是接近0左右两边的两个分界点。规格化后变化如下
最大负数(绝对值最小负数)变为1000 1011尾码变成了-((2^-1)-(2^-3)) = -0.375,结果是-0.375*2^-8
最小正数变为1000 0100 尾码变成了2^-1 = 0.5,结果是0.5*2^-8
所以规格后的范围是-1*2^7~-0.375*2^-8 0.5*2^-8~0.875*2^7